
| Visual Attention | ||
|
|
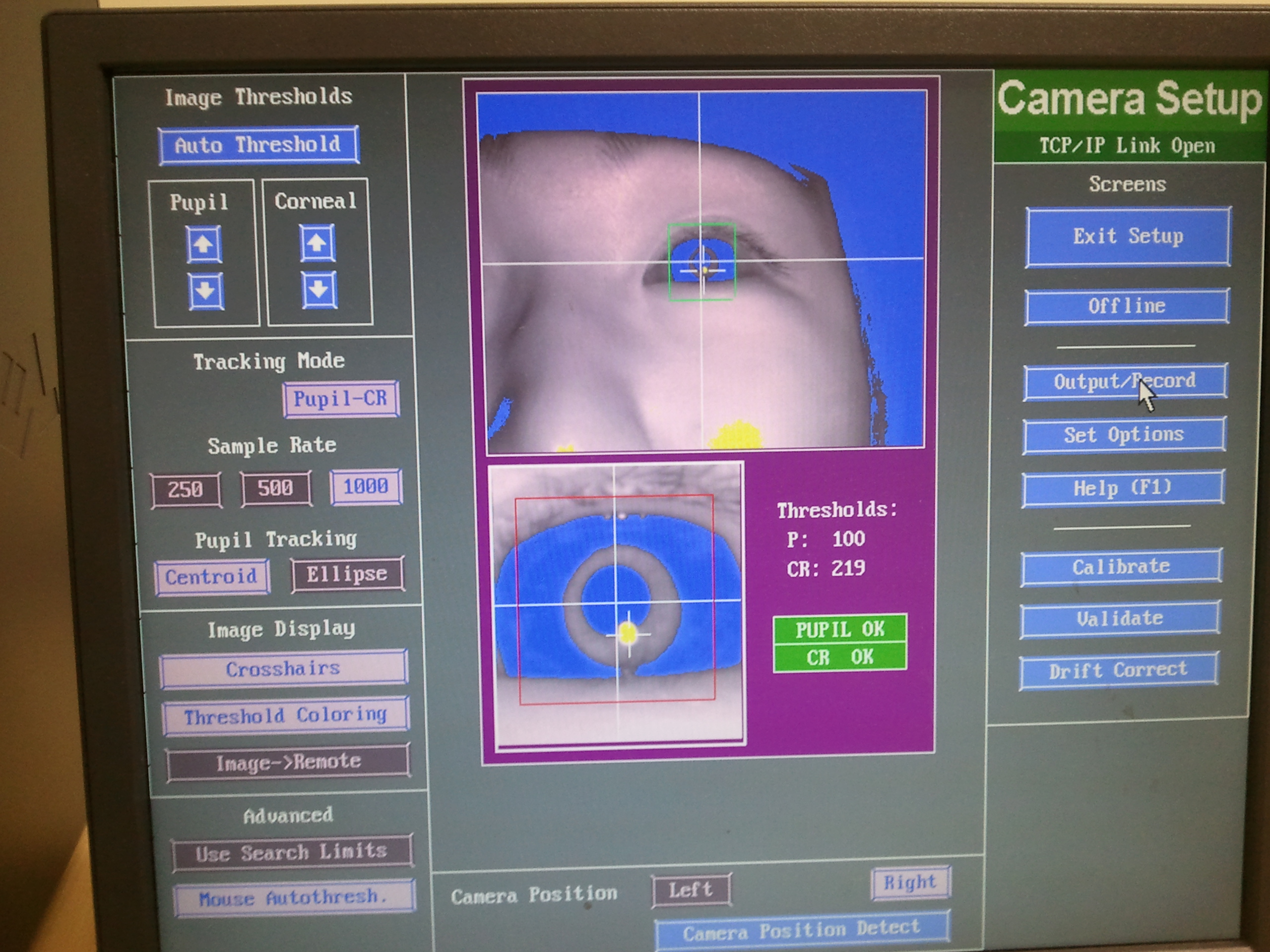
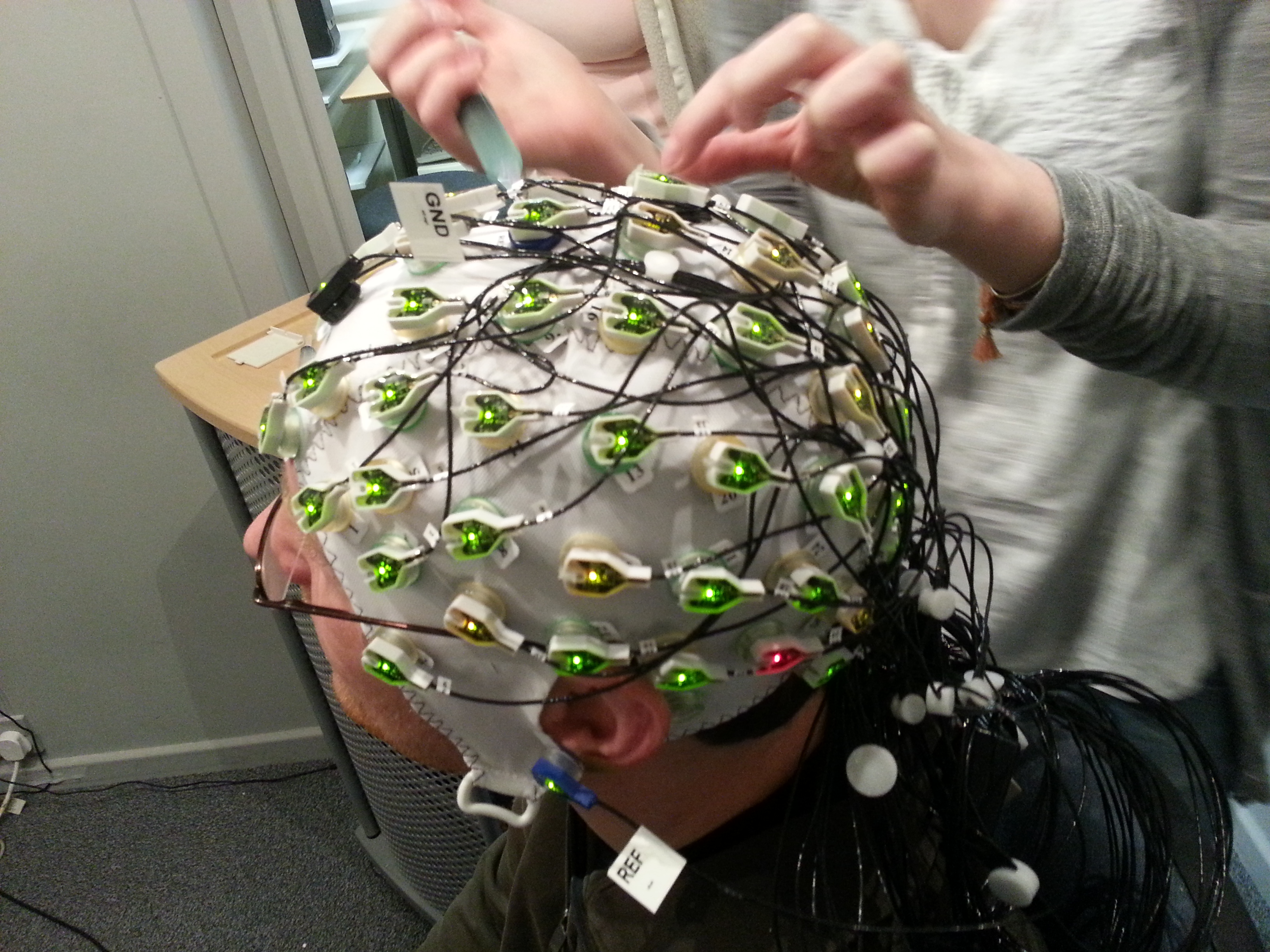
My main area of expertise is visual selective attention, and especially, how the visual system selects information from cluttered visual scenes. Specifically, I am trying to gain a deeper understanding about how much control we have over attention and eye movements, what the limitations are, and the factors and mechanisms underlying visual selection. My work has been greatly influenced by Anne Treisman's Feature Integration Theory, Jeremy Wolfe's Guided Search model, various saliency-based models of visual search, and the Contingent Capture Account of Chip Folk and Roger Remington. My own work shows that we indeed have a large amount of control over visual selective attention, as we can tune attention to sought-after objects which then quickly attract the gaze when they are present. There are however also bottom-up limitations to this goal-driven selection process that can completely frustrate our attempts to find an object. For my work, I'm using a variety of different methods, including eye-tracking, EEG and fMRI.
The Relational Account (Becker, 2010) One of my most important findings to date is that we don't tune attention to specific feature values such as red/green, or a particular size or shape, as predicted by other models of visual search. Rather, attention is tuned to relative features of objects such as redder, greener, yellower, darker/brighter and larger/smaller. So attention operates in a context-dependent manner. The visual system computes how a target object would differ from all other objects in a given situation, so for example, it computes whether an orange target would be yellower or redder than the surround. Then, depending on how the target differs from the surround, attention is directed either to the reddest or yellowest item in the display. This account of attention has become known as the 'relational account'. In collaboration with Aimee Martin and Zach Hamblin-Frohman, we are currently exploring whether visual short-term memory also encodes the relative features of objects, or only the specific feature values. How do we select the goal keeper in these two images?
According to the relational account, attention is biased to redder item when searching for the goal-keeper in the yellow team, and to yellower in the red team.
Emotions and Attention A second big topic of my research concerns how emotions can guide attention. Together with Gernot Horstmann, Ottmar Lipp, Alan Pegna and others, we investigated how emotional facial expressions and surprising stimuli can attract attention and our gaze. While emotions are very possibly the most important driving factor in our decisions and actions, our research so far suggests that attention and eye movements are more strongly influenced by perceptual factors than emotional factors. For example, in 'normal' angry and happy schematic faces (left images), the angry face is found faster than the happy face. However, by changing the contour of the face, the results pattern reverses, so that happy faces can be found faster than angry faces.
Changing the contour does not change the emotional expressions. Hence, our explanation is that the 'normal' angry faces can be found faster because the happy faces have a better Gestalt and can therefore be grouped and rejected more easily when they are the distractors. So -- faster search for angry faces is not driven by the emotional contents of the faces, but by their perceptual properties. The fact that attention and eye movements are strongly influenced by perceptual factors does not mean that emotional expressions or our own emotional states will exert no effects on attention. It only means that these effects may be more subtle and require new, ingenious paradigms to measure. In more recent studies, we have kept the stimuli the same and actively manipulated the participants' mood to study how emotional factors influence attention and eye movements. Our results so far are quite promising!
|